|
Pronounced like 'TomJade', or you can just call me Tom :) I'm an incoming CS Ph.D. student at the University of Melbourne, under the supervision of Prof. Eun-Jung Holden and Prof. Krista Ehinger. I was fortunate to have been working closely with Prof. Chen Chen on multi-modality video understanding. Email / Github / Google Scholar / LinkedIn |

|
|
[2025-02] Our GroundMoRE was accepted at CVPR 2025. [2024-02] Our paper OST: Refining Text Knowledge with Optimal Spatio-Temporal Descriptor for General Video Recognition was accepted at CVPR 2024. See you in Seattle! [2023-06] We won the 1st place of the AQTC Challenge at CVPR@23 LOng-form VidEo Understanding and Generation (LOVEU) Workshop. [2023-02] Our paper AShapeFormer: Semantics-Guided Object-Level Active Shape Encoding for 3D Object Detection via Transformers was accepted at CVPR 2023. |
|
|
|
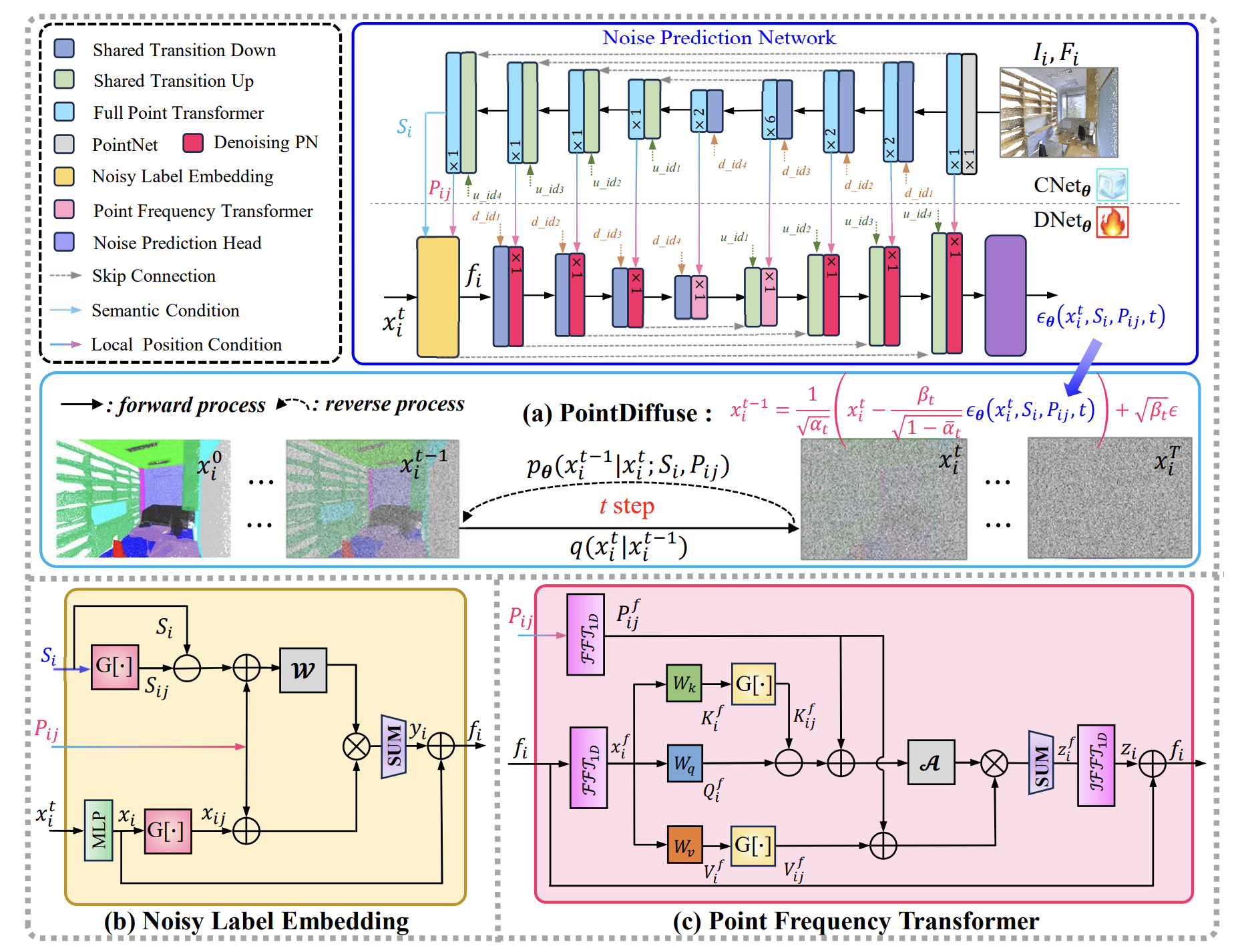
Yong He, Hongshan Yu, Mingtao Feng, Tongjia Chen, Zechuan Li, Anwaar Ulhaq, Saeed Anwar, Ajmal Mian Preprint, 2025 arXiv |
|
|
Yong He, Hongshan Yu, Muhammad Ibrahim, Xiaoyan Liu, Tongjia Chen, Anwaar Ulhaq, Ajmal Mian Preprint, 2024 arXiv |
|
|
|
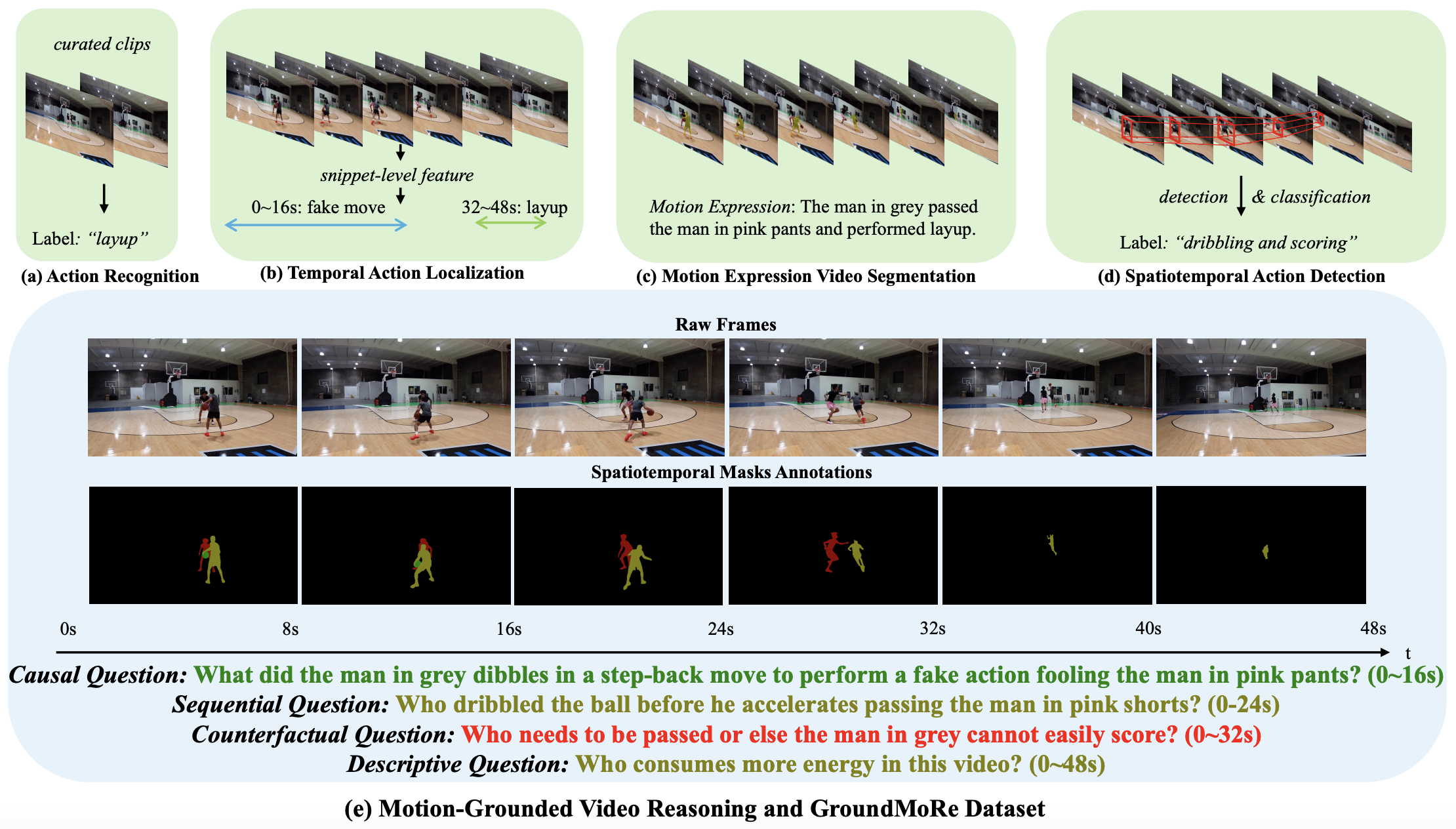
Andong Deng, Tongjia Chen, Shoubin Yu, Taojiannan Yang, Lincoln Spencer, Yapeng Tian, Ajmal Mian, Mohit Bansal, Chen Chen CVPR 2025 Project / arXiv |
|
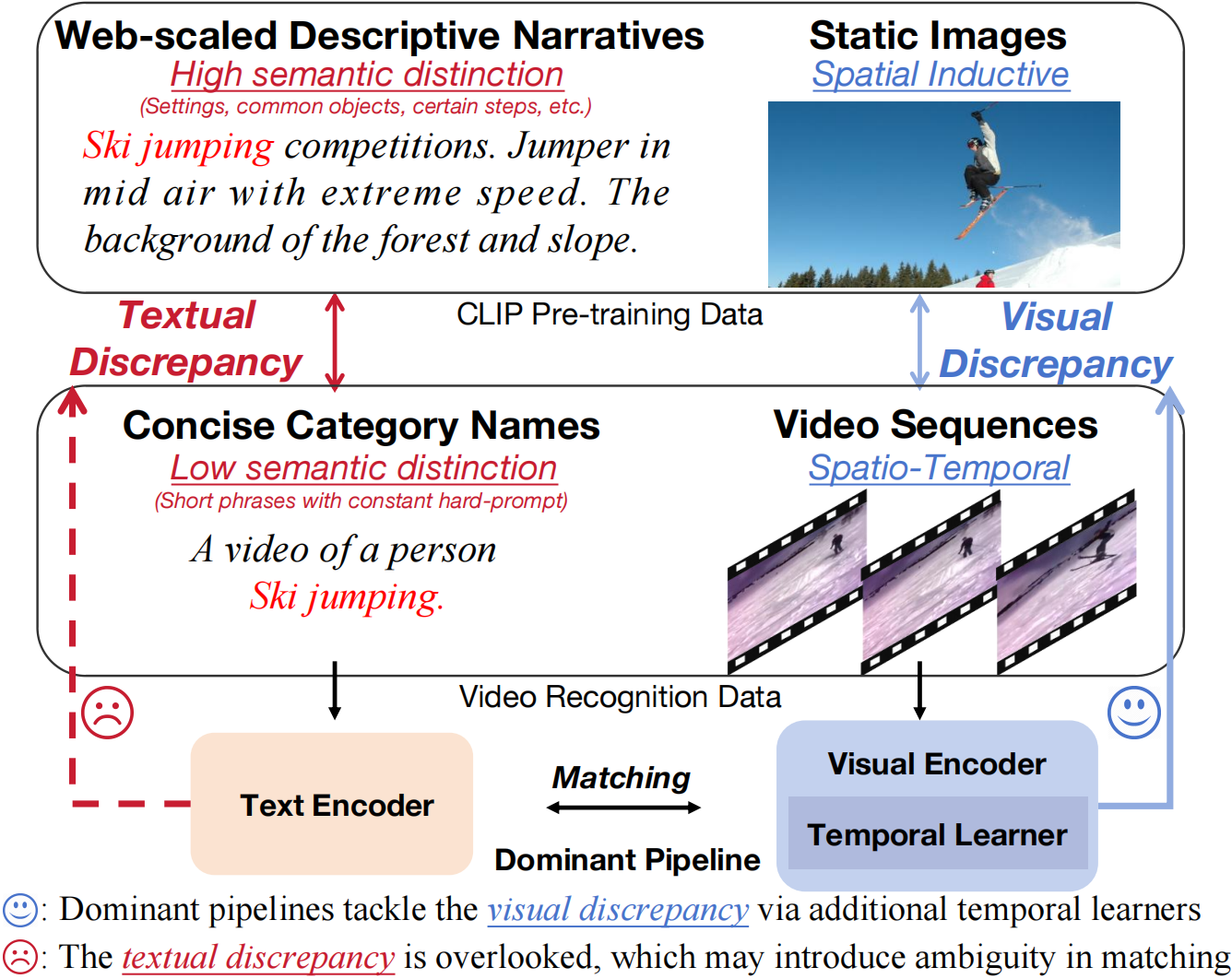
Tongjia Chen, Hongshan Yu, Zhengeng Yang, Zechuan Li, Wei Sun, Chen Chen CVPR 2024 Project / Code / arXiv |

|
Tongjia Chen, Hongshan Yu, Zhengeng Yang, Ming Li, Zechuan Li, Jingwen Wang, Wei Miao, Wei Sun, Chen Chen Tech Report, LOVEU Workshop, CVPR 2023 Code / Certificate |

|
Zechuan Li, Hongshan Yu, Zhengeng Yang, Tongjia Chen, Naveed Akhtar CVPR 2023 Project / Code / Video |
|
1st place of the AQTC Challenge at CVPR@23 LOng-form VidEo Understanding and Generation (LOVEU) Workshop. 2023 Academic Excellence Scholarship of HNU (Top 20%). 2021, 2022 Academic Excellence Scholarship of CUG (Top 10%). 2017-2020 |
|
|

|
Time: 2023.6.18 Title: First Place Solution to the CVPR'2023 AQTC Challenge: A Function-Interaction Centric Approach with Spatiotemporal Visual-Language Alignment Source: LOng-form VidEo Understanding and Generation (LOVEU) Workshop, CVPR 2023. Video / Slides |
|
CrossFitter / Culer / TIFOSI |
|
Updated at Jul. 2024
Thanks Jon Barron for this amazing template.
|